




Download full master thesis

Message me your comments through linkedin or send an email to adrian.lombera.cruz@gmail.com; it will help me invaluably to build synnergies with academics and other interested parties in the field in advance for my Ph.D
ABSTRACT
The platform lumpenproletariat
This thesis analyses the precarious conditions faced by data workers in the artificial intelligence sector. This profile is responsible for key tasks such as collecting, annotating and verifying data for training large-scale language models (LLM). Through a literature review and interviews with Kenyan workers, we examine the labour, social and economic structures that shape this labour figure, rendered invisible by outsourcing and offshoring practices.
The research is situated in a critical perspective of digital extractivism and the coloniality of data, denouncing how large technology corporations in the Global North outsource tasks to subcontractors in the Global South. These entities fragment tasks, make traceability difficult and hide the identity of the end clients, replicating historical logics of subordination and exploitation.
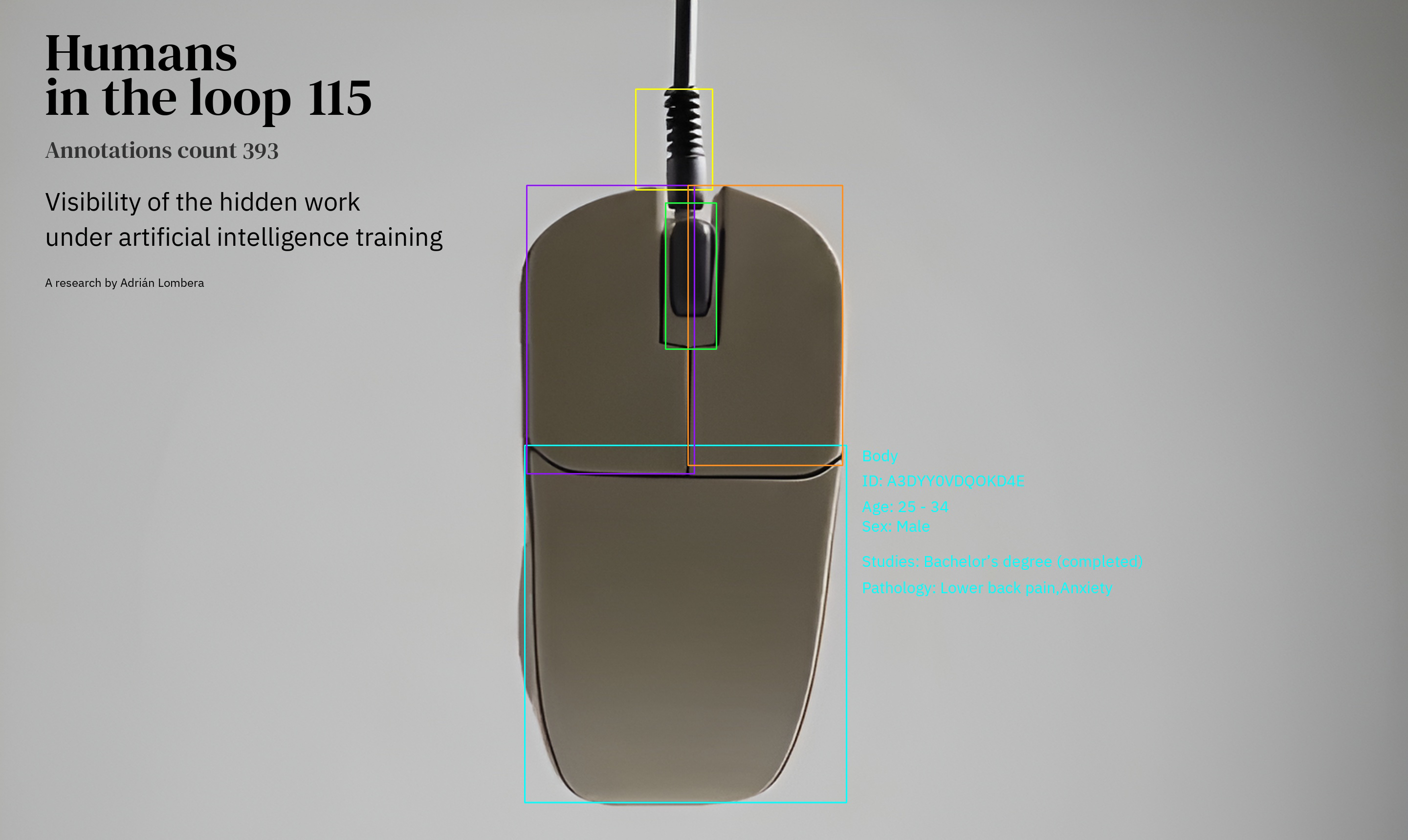
As a result, the project proposes the creation of a dataset designed to recognise a basic element in the day-to-day life of data workers - their computer mouse - and which incorporates metadata that makes visible the labour and social characteristics of the workers who participated in its elaboration.
key words: artificial intelligence, dataworkers, invisibilisation, dataset, datalabeling
INTRODUCTION
Work is not destroyed,
but displaced
The development and training of AI, in particular Large Language Models (LLM) and its Generative AI (GenAI), depends critically on a global supply chain that includes intensive human labour for the production, annotation and verification of data. This work, often referred to as micro work, is performed by a global, decentralised workforce of data workers. The World Bank estimates that 4.4% of the world's population works or has worked at some point in the production, annotation or verification of digital data in order for algorithms to perform their functions correctly. In addition, this typology of labour replicates extractivist flows that resemble those that appeared during European colonialisms. There are clear labour flows linking Africa to Europe and partially to Asia, as well as Latin America to North America with secondary flows, especially from Venezuela, Brazil and Argentina connected to Europe.
This research focuses on the systematic invisibilisation and strategic occlusion of the human contribution of the Global South. Large, artificially modelled corporations employ outsourced companies in developing countries. These in turn implement processes that make it difficult to identify end-customers by fragmenting tasks into small actions that cannot easily be linked to an end. This type of digital Taylorism keeps end customers obfuscated, and makes it difficult to understand the purpose of the tasks the data workers are working on.
In this context, data workers are not listed on the payroll of software development companies and are in turn prevented from knowing which companies the tasks come from. This lack of transparency is a key component in shaping the precarious working conditions that data workers inhabit: low wages, lack of social protection, algorithmic management, contractual instability and exposure to potentially harmful content without adequate psychological support.
These dynamics are often reminiscent of historical economic dependencies of colonialism and extractivism. Western companies through epistemic dominance extract the economic value generated through data work in populations largely located in the Global South and bring it to the Global North. Technology companies and corporations strategically conduct their operations in an unseen way to hide the impact on the development of their technology.
RESEARCH DESIGN
Research design
To assess the state of the art, we employed a combination of methods:
(M1) love & break-up letters, (M2) visual research, and (M3) a systematic review.
To address the questions “Which corporations use these job profiles?” and “How is this workforce structured from a business perspective?”, we conducted a systematic review (M3) and (M4) semi-structured interviews.
The issue of “how the labour rights of data workers are regulated?” was explored using the same methods (M3 and M4).
The question “What products do they work on?” was similarly addressed through the systematic review and semi-structured interviews.
To understand “What work do data workers do that should be made visible so that they are recognised?”, we combined (M1) love & hate letters with (M3) systematic review and (M4) semi-structured interviews.
Finally, to explore how we can highlight the precarious human labour behind datasets, I experimented with (M5) a crowdsourced task on Mechanical Turk involving image segmentation, paired with an (M6) anonymous qualitative survey, to create a (M7) traceable dataset that allowed for (M8) overlaying the labelling data with survey responses in an educational video that narrates the work involved and the conditions faced by data workers.
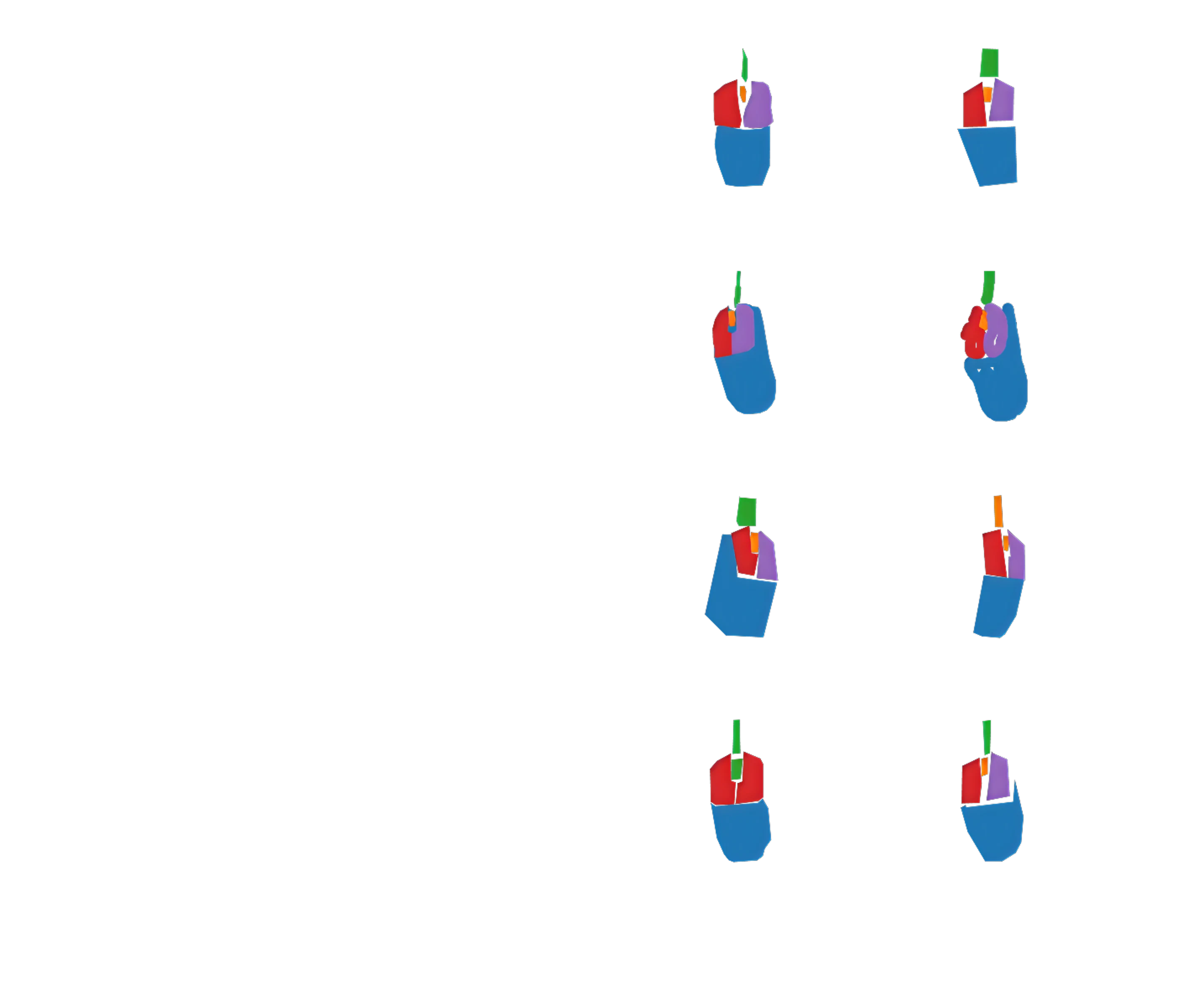
^ Above, an excerpt of the crowdsourced datalabeling task (M5), processed to show the rigurosity of annotations.

^ Excerpt frames of the video linking sociodemographic information and image segmentation data.
FUTURE LINES
Future lines
Reverse Audits and Contextual Traceability for provenance
Traceability in generative artificial intelligence opens up three complementary lines of application with high transformative potential.
Firstly, as a labour supervision tool, it allows the incorporation of labour and socio-demographic metadata linked to each contribution in the AI value chain, making it possible to audit who generated the data, under what conditions, and for which client.
Emerging frameworks such as the Croissant metadata standard, developed by MLCommons and Google, already propose structured fields to document the provenance of data, including worker participation and licensing details.
Similarly, initiatives like the Partnership on AI’s Guidelines for Enriched Data Sourcing recommend embedding ethical criteria—such as fair wages, working conditions, and transparency—directly into the data lifecycle.
Secondly, it acts as an analytical tool for detecting bias by enabling reverse audits that link annotative decisions to specific social contexts, helping to identify structural patterns of exclusion or distortion in models. This approach makes it possible to move beyond generic bias detection and instead examine how particular worker demographics, local norms, or economic constraints influence labeling patterns.
This line of research seeks to develop an interoperable standard that transforms each data point into an auditable unit, carrying its own traceable labour and epistemic signature. It would not only facilitate regulatory oversight in opaque data pipelines but also empower both workers and auditors to demand accountability, transparency, and justice within the AI development process.
Collaborative AI Training
for Pluriversal Education
Educational institutions can serve as spaces for collaboratively training AI models in an ethical, participatory, and culturally inclusive way. By actively involving not only students and faculty but also underrepresented communities—particularly from the Global South—in the creation and curation of datasets, universities can promote more plural, situated, and critical engagements with AI. This approach aims to embed multiple worldviews into the model architecture, fostering systems that are epistemically diverse.
This could mean working alongside migrant, diasporic, and local racialized communities to collectively annotate, select, and challenge the data that feeds educational AI tools. Platforms such as Argilla enable collaborative annotation between engineers, domain experts, and non-experts, making it possible to integrate lived experience and contextual knowledge directly into model training. Tools like Model Share AI support students in co-developing and evaluating models in teams, creating opportunities for reflexive, multilingual, and cross-cultural experimentation.
Cases like SynthBio, where human editors reduced bias in machine-generated content, show that collaborative workflows can mitigate epistemic dominance and reveal latent conflicts between annotation norms across cultural contexts. Ultimately, these practices show that training AI in educational settings can be a transformative act: not just to improve accuracy, but to build technologies aligned with justice, plurality, and inclusive futures.
REFERENCES
Readings involved
Anwar, M. (2023). Value Chains of AI: Data Training Firms Platforms and Workers. University of Edinburgh. https://orcid.org/0000-0002-5213-4022
Braz, M. V., Tubaro, P., & Casilli, A. A. (2024). Fabricar os dados: O trabalho por trás da Inteligência Artificial. http://doi.org/10.1590/15174522-111017
Casilli, A. A. (2024). Digital Labor and the Inconspicuous Production of Artificial Intelligence. https://doi.org/10.48550/arXiv.2410.05910
Casilli, A. A., & Tubaro, P. (2023). An end-to-end approach to ethical AI: Socio-economic dimensions of the production and deployment of automated technologies. Handbook of Digital Social Science.
Casilli, A. A., Tubaro, P., Cornet, M., Le Ludec, C., Torres-Cierpe, J., & Braz, M. V. (2021). Global inequalities in the production of artificial intelligence: A four-country study on data work. The Handbook of Digital Labor https://doi.org/10.48550/arXiv.2410.14230
Chaudhuri, B., & Chandhiramowuli, S. (2024). Tracing the displacement of data work in AI: A political economy of “human-in-the-loop.” Engaging Science, Technology, and Society, 10(1–2). https://doi.org/10.17351/ests2024.2983
Ekbia, H., & Nardi, B. (2014). Heteromation and its (dis)contents: The invisible division of labor between humans and machines. First Monday. https://doi.org/10.5210/fm.v19i6.5331
Evers, C., Khurana, M., Mata, T., Soper, L., & Stilgoe, J. (2022). Ghost workers report—Empowering the invisible labour behind artificial intelligence.
Hung, K.-H. (2024). Artificial intelligence as planetary assemblages of coloniality: The new power architecture driving a tiered global data economy. Big Data & Society, 11(4). https:/ doi.org/10.1177/20539517241289443
Le Ludec, C., Cornet, M., & Casilli, A. A. (2023). The problem with annotation: Human labour and outsourcing between France and Madagascar. Big Data & Society, 10(2). https://doi.org/10.1177/20539517231188723
Muldoon, J., Cant, C., Wu, B., & Graham, M. (2024). A typology of artificial intelligence data work. Big Data & Society, 11(1). https://doi.org/10.1177/20539517241232632
Newlands, G. (2021). Lifting the curtain: Strategic visibility of human labour in AI-as-a-Service. Big Data & Society, 8(1), 20539517211016026. https://doi.org/10.1177/20539517211016026
Posada, J. (2022). The Coloniality of Data Work: Power and Inequality in Outsourced Data Production for Machine Learning. Faculty of Information, University of Toronto.
Rothschild, A., Wang, D., Jayakumar Vilvanathan, N., Wilcox, L., DiSalvo, C., & DiSalvo, B. (2024). The problems with proxies: Making data work visible through requester practices. Proceedings of the AAAI/ACM Conference on AI, Ethics, and Society, 7, 1255–1268. https://doi.org/10.1609/aies.v7i1.31721
Tubaro, P., Casilli, A. A., Cornet, M., Le Ludec, C., & Torres-Cierpe, J. (2025). Where does AI come from? A global case study across Europe, Africa, and Latin America. New Political Economy, 1–14. https://doi.org/10.1080/13563467.2025.2462137
Tubaro, P., Casilli, A. A., & Coville, M. (2020). The trainer, the verifier, the imitator: Three ways in which human platform workers support artificial intelligence. Big Data & Society, 7(1). https://doi.org/10.1177/2053951720919776
Full bibliography in the master thesis

INTERVIEWEES ACKNOWLEDGMENTS

plus 276 anonymous datalabelers from Amazon Mechanical Turk.
For the people behind AI curtain.

Download full master thesis
Play video


DEVELOPED FOR
IN COLLABORATION WITH
ABSTRACT
The platform lumpenproletariat
This thesis analyses the precarious conditions faced by data workers in the artificial intelligence sector. This profile is responsible for key tasks such as collecting, annotating and verifying data for training large-scale language models (LLM). Through a literature review and interviews with Kenyan workers, we examine the labour, social and economic structures that shape this labour figure, rendered invisible by outsourcing and offshoring practices.
The research is situated in a critical perspective of digital extractivism and the coloniality of data, denouncing how large technology corporations in the Global North outsource tasks to subcontractors in the Global South. These entities fragment tasks, make traceability difficult and hide the identity of the end clients, replicating historical logics of subordination and exploitation.
As a result, the project proposes the creation of a dataset designed to recognise a basic element in the day-to-day life of data workers - their computer mouse - and which incorporates metadata that makes visible the labour and social characteristics of the workers who participated in its elaboration.
key words: artificial intelligence, dataworkers, invisibilisation, dataset, datalabeling
INTRODUCTION
Work is not destroyed,
but displaced
The development and training of AI, in particular Large Language Models (LLM) and its Generative AI (GenAI), depends critically on a global supply chain that includes intensive human labour for the production, annotation and verification of data. This work, often referred to as micro work, is performed by a global, decentralised workforce of data workers. The World Bank estimates that 4.4% of the world's population works or has worked at some point in the production, annotation or verification of digital data in order for algorithms to perform their functions correctly. In addition, this typology of labour replicates extractivist flows that resemble those that appeared during European colonialisms. There are clear labour flows linking Africa to Europe and partially to Asia, as well as Latin America to North America with secondary flows, especially from Venezuela, Brazil and Argentina connected to Europe.
This research focuses on the systematic invisibilisation and strategic occlusion of the human contribution of the Global South. Large, artificially modelled corporations employ outsourced companies in developing countries. These in turn implement processes that make it difficult to identify end-customers by fragmenting tasks into small actions that cannot easily be linked to an end. This type of digital Taylorism keeps end customers obfuscated, and makes it difficult to understand the purpose of the tasks the data workers are working on.
In this context, data workers are not listed on the payroll of software development companies and are in turn prevented from knowing which companies the tasks come from. This lack of transparency is a key component in shaping the precarious working conditions that data workers inhabit: low wages, lack of social protection, algorithmic management, contractual instability and exposure to potentially harmful content without adequate psychological support.
These dynamics are often reminiscent of historical economic dependencies of colonialism and extractivism. Western companies through epistemic dominance extract the economic value generated through data work in populations largely located in the Global South and bring it to the Global North. Technology companies and corporations strategically conduct their operations in an unseen way to hide the impact on the development of their technology.
RESEARCH DESIGN
Research design
To assess the state of the art, we employed a combination of methods:
(M1) love & break-up letters, (M2) visual research, and (M3) a systematic review.
To address the questions “Which corporations use these job profiles?” and “How is this workforce structured from a business perspective?”, we conducted a systematic review (M3) and (M4) semi-structured interviews.
The issue of “how the labour rights of data workers are regulated?” was explored using the same methods (M3 and M4).
The question “What products do they work on?” was similarly addressed through the systematic review and semi-structured interviews.
To understand “What work do data workers do that should be made visible so that they are recognised?”, we combined (M1) love & hate letters with (M3) systematic review and (M4) semi-structured interviews.
Finally, to explore how we can highlight the precarious human labour behind datasets, I experimented with (M5) a crowdsourced task on Mechanical Turk involving image segmentation, paired with an (M6) anonymous qualitative survey, to create a (M7) traceable dataset that allowed for (M8) overlaying the labelling data with survey responses in an educational video that narrates the work involved and the conditions faced by data workers.
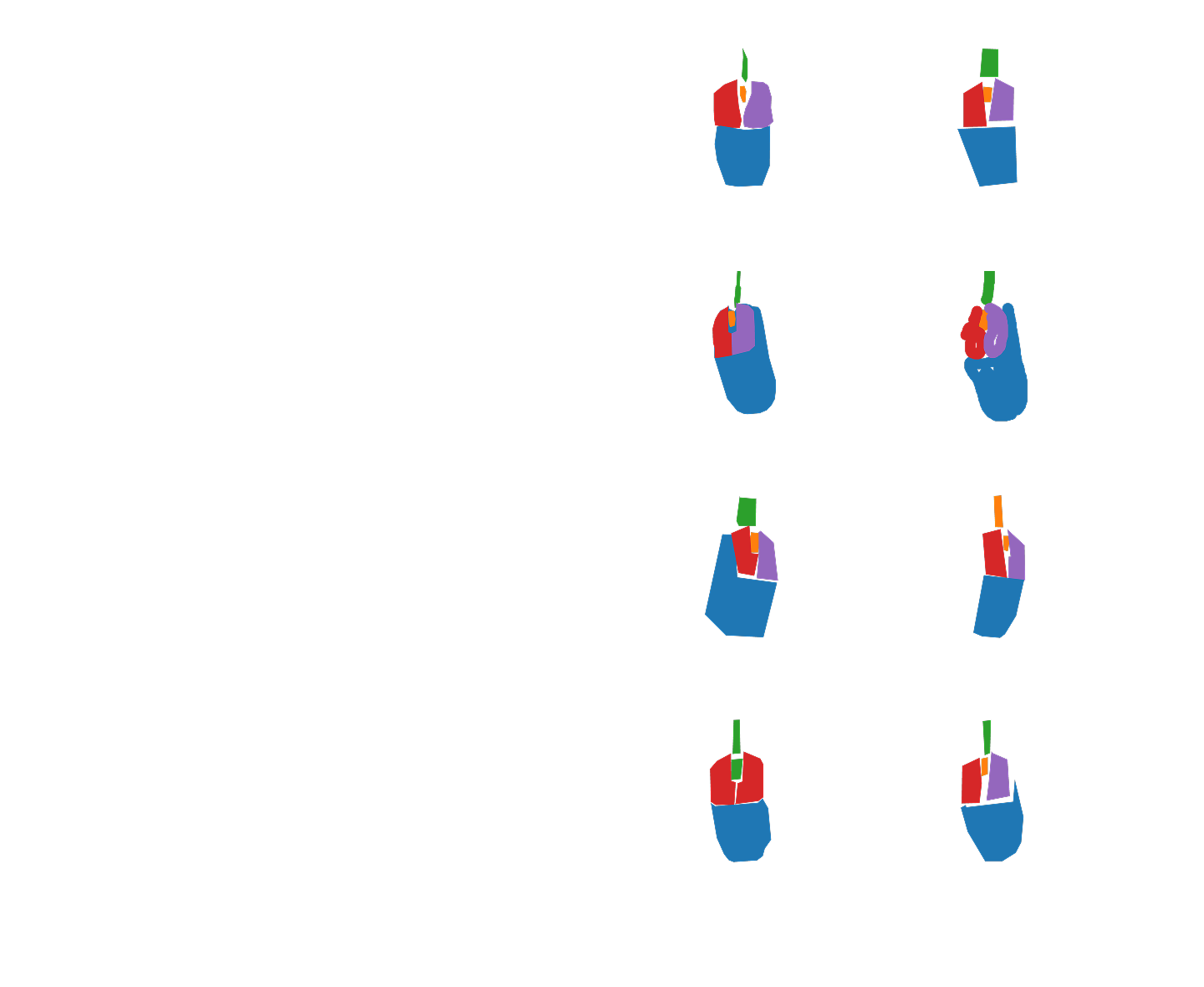
^ An excerpt of the crowdsourced datalabeling task (M5), processed to show the rigurosity of annotations.
^ Excerpt frames of the video, linking sociodemographic information and image segmentation data.
FUTURE LINES
Future lines
Reverse Audits and Contextual Traceability for provenance
Traceability in generative artificial intelligence opens up three complementary lines of application with high transformative potential.
Firstly, as a labour supervision tool, it allows the incorporation of labour and socio-demographic metadata linked to each contribution in the AI value chain, making it possible to audit who generated the data, under what conditions, and for which client.
Emerging frameworks such as the Croissant metadata standard, developed by MLCommons and Google, already propose structured fields to document the provenance of data, including worker participation and licensing details.
Similarly, initiatives like the Partnership on AI’s Guidelines for Enriched Data Sourcing recommend embedding ethical criteria—such as fair wages, working conditions, and transparency—directly into the data lifecycle.
Secondly, it acts as an analytical tool for detecting bias by enabling reverse audits that link annotative decisions to specific social contexts, helping to identify structural patterns of exclusion or distortion in models. This approach makes it possible to move beyond generic bias detection and instead examine how particular worker demographics, local norms, or economic constraints influence labeling patterns.
This line of research seeks to develop an interoperable standard that transforms each data point into an auditable unit, carrying its own traceable labour and epistemic signature. It would not only facilitate regulatory oversight in opaque data pipelines but also empower both workers and auditors to demand accountability, transparency, and justice within the AI development process.
Collaborative AI Training
for Pluriversal Education
Educational institutions can serve as spaces for collaboratively training AI models in an ethical, participatory, and culturally inclusive way. By actively involving not only students and faculty but also underrepresented communities—particularly from the Global South—in the creation and curation of datasets, universities can promote more plural, situated, and critical engagements with AI. This approach aims to embed multiple worldviews into the model architecture, fostering systems that are not only technically robust but also epistemically diverse and socially just.
This could mean working alongside migrant, diasporic, and local racialized communities to collectively annotate, select, and challenge the data that feeds educational AI tools. Platforms such as Argilla enable collaborative annotation between engineers, domain experts, and non-experts, making it possible to integrate lived experience and contextual knowledge directly into model training. Tools like Model Share AI support students in co-developing and evaluating models in teams, creating opportunities for reflexive, multilingual, and cross-cultural experimentation.
Cases like SynthBio, where human editors reduced bias in machine-generated content, show that collaborative workflows can mitigate epistemic dominance and reveal latent conflicts between annotation norms across cultural contexts. Ultimately, these practices show that training AI in educational settings can be a transformative act: not just to improve accuracy, but to build technologies aligned with justice, plurality, and inclusive futures.
REFERENCES
Readings involved
Anwar, M. (2023). Value Chains of AI: Data Training Firms Platforms and Workers. University of Edinburgh. https://orcid.org/0000-0002-5213-4022
Braz, M. V., Tubaro, P., & Casilli, A. A. (2024). Fabricar os dados: O trabalho por trás da Inteligência Artificial.
Casilli, A. A. (2024). Digital Labor and the Inconspicuous Production of Artificial Intelligence.
Casilli, A. A., & Tubaro, P. (2023). An end-to-end approach to ethical AI: Socio-economic dimensions of the production and deployment of automated technologies.
Casilli, A. A., Tubaro, P., Cornet, M., Le Ludec, C., Torres-Cierpe, J., & Braz, M. V. (2021). Global inequalities in the production of artificial intelligence: A four-country study on data work.
Chaudhuri, B., & Chandhiramowuli, S. (2024). Tracing the displacement of data work in AI: A political economy of “human-in-the-loop.” Engaging Science, Technology, and Society, 10(1–2). https://doi.org/10.17351/ests2024.2983
Ekbia, H., & Nardi, B. (2014). Heteromation and its (dis)contents: The invisible division of labor between humans and machines. First Monday. https://doi.org/10.5210/fm.v19i6.5331
Evers, C., Khurana, M., Mata, T., Soper, L., & Stilgoe, J. (2022). Ghost workers report—Empowering the invisible labour behind artificial intelligence.
Hung, K.-H. (2024). Artificial intelligence as planetary assemblages of coloniality: The new power architecture driving a tiered global data economy. Big Data & Society, 11(4), 20539517241289443. https:/ doi.org/10.1177/20539517241289443
Le Ludec, C., Cornet, M., & Casilli, A. A. (2023). The problem with annotation: Human labour and outsourcing between France and Madagascar. Big Data & Society, 10(2), 20539517231188723. https://doi.org/10.1177/20539517231188723
Muldoon, J., Cant, C., Wu, B., & Graham, M. (2024). A typology of artificial intelligence data work. Big Data & Society, 11(1), 20539517241232632. https://doi.org/10.1177/20539517241232632
Newlands, G. (2021). Lifting the curtain: Strategic visibility of human labour in AI-as-a-Service. Big Data & Society, 8(1), 20539517211016026. https://doi.org/10.1177/20539517211016026
Posada, J. (2022). The Coloniality of Data Work: Power and Inequality in Outsourced Data Production for Machine Learning. Faculty of Information, University of Toronto.
Rothschild, A., Wang, D., Jayakumar Vilvanathan, N., Wilcox, L., DiSalvo, C., & DiSalvo, B. (2024). The problems with proxies: Making data work visible through requester practices. Proceedings of the AAAI/ACM Conference on AI, Ethics, and Society, 7, 1255–1268. https://doi.org/10.1609/aies.v7i1.31721
Tubaro, P., Casilli, A. A., Cornet, M., Le Ludec, C., & Torres-Cierpe, J. (2025). Where does AI come from? A global case study across Europe, Africa, and Latin America. New Political Economy, 1–14. https://doi.org/10.1080/13563467.2025.2462137
Tubaro, P., Casilli, A. A., & Coville, M. (2020). The trainer, the verifier, the imitator: Three ways in which human platform workers support artificial intelligence. Big Data & Society, 7(1), 2053951720919776. https://doi.org/10.1177/2053951720919776
Full bibliography in the master thesis
INTERVIEWEES ACKNOWLEDGMENTS
plus 276 anonymous datalabelers from Amazon Mechanical Turk.
For the people behind AI curtain.

ABSTRACT
The platform lumpenproletariat
This thesis analyses the precarious conditions faced by data workers in the artificial intelligence sector. This profile is responsible for key tasks such as collecting, annotating and verifying data for training large-scale language models (LLM). Through a literature review and interviews with Kenyan workers, we examine the labour, social and economic structures that shape this labour figure, rendered invisible by outsourcing and offshoring practices.
The research is situated in a critical perspective of digital extractivism and the coloniality of data, denouncing how large technology corporations in the Global North outsource tasks to subcontractors in the Global South. These entities fragment tasks, make traceability difficult and hide the identity of the end clients, replicating historical logics of subordination and exploitation.
As a result, the project proposes the creation of a dataset designed to recognise a basic element in the day-to-day life of data workers - their computer mouse - and which incorporates metadata that makes visible the labour and social characteristics of the workers who participated in its elaboration.
key words: artificial intelligence, dataworkers, invisibilisation, dataset, datalabeling
INTRODUCTION
Work is not destroyed,
but displaced
The development and training of AI, in particular Large Language Models (LLM) and its Generative AI (GenAI), depends critically on a global supply chain that includes intensive human labour for the production, annotation and verification of data. This work, often referred to as micro work, is performed by a global, decentralised workforce of data workers. The World Bank estimates that 4.4% of the world's population works or has worked at some point in the production, annotation or verification of digital data in order for algorithms to perform their functions correctly. In addition, this typology of labour replicates extractivist flows that resemble those that appeared during European colonialisms. There are clear labour flows linking Africa to Europe and partially to Asia, as well as Latin America to North America with secondary flows, especially from Venezuela, Brazil and Argentina connected to Europe.
This research focuses on the systematic invisibilisation and strategic occlusion of the human contribution of the Global South. Large, artificially modelled corporations employ outsourced companies in developing countries. These in turn implement processes that make it difficult to identify end-customers by fragmenting tasks into small actions that cannot easily be linked to an end. This type of digital Taylorism keeps end customers obfuscated, and makes it difficult to understand the purpose of the tasks the data workers are working on.
In this context, data workers are not listed on the payroll of software development companies and are in turn prevented from knowing which companies the tasks come from. This lack of transparency is a key component in shaping the precarious working conditions that data workers inhabit: low wages, lack of social protection, algorithmic management, contractual instability and exposure to potentially harmful content without adequate psychological support.
These dynamics are often reminiscent of historical economic dependencies of colonialism and extractivism. Western companies through epistemic dominance extract the economic value generated through data work in populations largely located in the Global South and bring it to the Global North. Technology companies and corporations strategically conduct their operations in an unseen way to hide the impact on the development of their technology.
RESEARCH DESIGN
Research design
To assess the state of the art, we employed a combination of methods:
(M1) love & break-up letters, (M2) visual research, and (M3) a systematic review.
To address the questions “Which corporations use these job profiles?” and “How is this workforce structured from a business perspective?”, we conducted a systematic review (M3) and (M4) semi-structured interviews.
The issue of “how the labour rights of data workers are regulated?” was explored using the same methods (M3 and M4).
The question “What products do they work on?” was similarly addressed through the systematic review and semi-structured interviews.
To understand “What work do data workers do that should be made visible so that they are recognised?”, we combined (M1) love & hate letters with (M3) systematic review and (M4) semi-structured interviews.
Finally, to explore how we can highlight the precarious human labour behind datasets, I experimented with (M5) a crowdsourced task on Mechanical Turk involving image segmentation, paired with an (M6) anonymous qualitative survey, to create a (M7) traceable dataset that allowed for (M8) overlaying the labelling data with survey responses in an educational video that narrates the work involved and the conditions faced by data workers.
^ An excerpt of the crowdsourced datalabeling task (M5), processed to show the rigurosity of annotations.
^ Excerpt frames of the video, linking sociodemographic information and image segmentation data.
FUTURE LINES
Future lines
Reverse Audits and Contextual Traceability for provenance
Traceability in generative artificial intelligence opens up three complementary lines of application with high transformative potential.
Firstly, as a labour supervision tool, it allows the incorporation of labour and socio-demographic metadata linked to each contribution in the AI value chain, making it possible to audit who generated the data, under what conditions, and for which client.
Emerging frameworks such as the Croissant metadata standard, developed by MLCommons and Google, already propose structured fields to document the provenance of data, including worker participation and licensing details.
Similarly, initiatives like the Partnership on AI’s Guidelines for Enriched Data Sourcing recommend embedding ethical criteria—such as fair wages, working conditions, and transparency—directly into the data lifecycle.
Secondly, it acts as an analytical tool for detecting bias by enabling reverse audits that link annotative decisions to specific social contexts, helping to identify structural patterns of exclusion or distortion in models. This approach makes it possible to move beyond generic bias detection and instead examine how particular worker demographics, local norms, or economic constraints influence labeling patterns.
This line of research seeks to develop an interoperable standard that transforms each data point into an auditable unit, carrying its own traceable labour and epistemic signature. It would not only facilitate regulatory oversight in opaque data pipelines but also empower both workers and auditors to demand accountability, transparency, and justice within the AI development process.
Collaborative AI Training
for Pluriversal Education
Educational institutions can serve as spaces for collaboratively training AI models in an ethical, participatory, and culturally inclusive way. By actively involving not only students and faculty but also underrepresented communities—particularly from the Global South—in the creation and curation of datasets, universities can promote more plural, situated, and critical engagements with AI. This approach aims to embed multiple worldviews into the model architecture, fostering systems that are epistemically diverse.
This could mean working alongside migrant, diasporic, and local racialized communities to collectively annotate, select, and challenge the data that feeds educational AI tools. Platforms such as Argilla enable collaborative annotation between engineers, domain experts, and non-experts, making it possible to integrate lived experience and contextual knowledge directly into model training. Tools like Model Share AI support students in co-developing and evaluating models in teams, creating opportunities for reflexive, multilingual, and cross-cultural experimentation.
Cases like SynthBio, where human editors reduced bias in machine-generated content, show that collaborative workflows can mitigate epistemic dominance and reveal latent conflicts between annotation norms across cultural contexts. Ultimately, these practices show that training AI in educational settings can be a transformative act: not just to improve accuracy, but to build technologies aligned with justice, plurality, and inclusive futures.
REFERENCES
Readings involved
Anwar, M. (2023). Value Chains of AI: Data Training Firms Platforms and Workers. University of Edinburgh. https://orcid.org/0000-0002-5213-4022
Braz, M. V., Tubaro, P., & Casilli, A. A. (2024). Fabricar os dados: O trabalho por trás da Inteligência Artificial. http://doi.org/10.1590/15174522-111017
Casilli, A. A. (2024). Digital Labor and the Inconspicuous Production of Artificial Intelligence. https://doi.org/10.48550/arXiv.2410.05910
Casilli, A. A., & Tubaro, P. (2023). An end-to-end approach to ethical AI: Socio-economic dimensions of the production and deployment of automated technologies. Handbook of Digital Social Science.
Casilli, A. A., Tubaro, P., Cornet, M., Le Ludec, C., Torres-Cierpe, J., & Braz, M. V. (2021). Global inequalities in the production of artificial intelligence: A four-country study on data work. The Handbook of Digital Labor https://doi.org/10.48550/arXiv.2410.14230
Chaudhuri, B., & Chandhiramowuli, S. (2024). Tracing the displacement of data work in AI: A political economy of “human-in-the-loop.” Engaging Science, Technology, and Society, 10(1–2). https://doi.org/10.17351/ests2024.2983
Ekbia, H., & Nardi, B. (2014). Heteromation and its (dis)contents: The invisible division of labor between humans and machines. First Monday. https://doi.org/10.5210/fm.v19i6.5331
Evers, C., Khurana, M., Mata, T., Soper, L., & Stilgoe, J. (2022). Ghost workers report—Empowering the invisible labour behind artificial intelligence.
Hung, K.-H. (2024). Artificial intelligence as planetary assemblages of coloniality: The new power architecture driving a tiered global data economy. Big Data & Society, 11(4). https:/ doi.org/10.1177/20539517241289443
Le Ludec, C., Cornet, M., & Casilli, A. A. (2023). The problem with annotation: Human labour and outsourcing between France and Madagascar. Big Data & Society, 10(2). https://doi.org/10.1177/20539517231188723
Muldoon, J., Cant, C., Wu, B., & Graham, M. (2024). A typology of artificial intelligence data work. Big Data & Society, 11(1). https://doi.org/10.1177/20539517241232632
Newlands, G. (2021). Lifting the curtain: Strategic visibility of human labour in AI-as-a-Service. Big Data & Society, 8(1), 20539517211016026. https://doi.org/10.1177/20539517211016026
Posada, J. (2022). The Coloniality of Data Work: Power and Inequality in Outsourced Data Production for Machine Learning. Faculty of Information, University of Toronto.
Rothschild, A., Wang, D., Jayakumar Vilvanathan, N., Wilcox, L., DiSalvo, C., & DiSalvo, B. (2024). The problems with proxies: Making data work visible through requester practices. Proceedings of the AAAI/ACM Conference on AI, Ethics, and Society, 7, 1255–1268. https://doi.org/10.1609/aies.v7i1.31721
Tubaro, P., Casilli, A. A., Cornet, M., Le Ludec, C., & Torres-Cierpe, J. (2025). Where does AI come from? A global case study across Europe, Africa, and Latin America. New Political Economy, 1–14. https://doi.org/10.1080/13563467.2025.2462137
Tubaro, P., Casilli, A. A., & Coville, M. (2020). The trainer, the verifier, the imitator: Three ways in which human platform workers support artificial intelligence. Big Data & Society, 7(1). https://doi.org/10.1177/2053951720919776
Full bibliography in the master thesis
INTERVIEWEES ACKNOWLEDGMENTS
plus 276 anonymous datalabelers from Amazon Mechanical Turk.
For the people behind AI curtain.
